


服务器反爬虫攻略:Apache/Nginx/PHP禁止某些User Agent抓取网站
我们都知道网络上的爬虫非常多,有对网站收录有益的,比如百度蜘蛛(Baiduspider),也有不但不遵守 robots 规则对服务器造成压力,还不能为网站带来流量的无用爬虫,比如宜搜蜘蛛(YisouSpider)(最新补充:宜搜蜘蛛已被 UC 神马搜索收购!所以本文已去掉宜搜蜘蛛的禁封!==>相关文章)。最近发现 nginx 日志中出现了好多宜搜等垃圾的抓取记录,于是整理收集了网络上各种禁止垃圾蜘蛛爬站的方法,在给自己网做设置的同时,也给各位站长提供参考。
一、Apache
①、通过修改 .htaccess 文件
修改网站目录下的.htaccess,添加如下代码即可(2 种代码任选):
可用代码 (1):
RewriteEngine OnRewriteCond %{HTTP_USER_AGENT} (^$|FeedDemon|Indy Library|Alexa Toolbar|AskTbFXTV|AhrefsBot|CrawlDaddy|CoolpadWebkit|Java|Feedly|UniversalFeedParser|ApacheBench|Microsoft URL Control|Swiftbot|ZmEu|oBot|jaunty|Python–urllib|lightDeckReports Bot|YYSpider|DigExt|HttpClient|MJ12bot|heritrix|EasouSpider|Ezooms) [NC]RewriteRule ^(.*)$ – [F]
?可用代码 (2):
找到如下类似位置,根据以下代码 新增 / 修改,然后重启 Apache 即可:
二、Nginx 代码
进入到 nginx 安装目录下的 conf 目录,将如下代码保存为?agent_deny.conf
cd /usr/local/nginx/conf
vim?agent_deny.conf
#禁止Scrapy等工具的抓取if ($http_user_agent ~* (Scrapy|Curl|HttpClient)) {???? return 403;}#禁止指定UA及UA为空的访问if ($http_user_agent ~* “FeedDemon|Indy Library|Alexa Toolbar|AskTbFXTV|AhrefsBot|CrawlDaddy|CoolpadWebkit|Java|Feedly|UniversalFeedParser|ApacheBench|Microsoft URL Control|Swiftbot|ZmEu|oBot|jaunty|Python-urllib|lightDeckReports Bot|YYSpider|DigExt|HttpClient|MJ12bot|heritrix|EasouSpider|Ezooms|^$” ) {???? return 403;????????????}#禁止非GET|HEAD|POST方式的抓取if ($request_method !~ ^(GET|HEAD|POST)$) {????return 403;}
然后,在网站相关配置中的 ?location / { ?之后插入如下代码:
如下的配置:
[marsge@Mars_Server ~]$ cat /usr/local/nginx/conf/zhangge.conflocation / {????????try_files $uri $uri/ /index.php?$args;????????#这个位置新增1行:????????include agent_deny.conf;????????rewrite ^/sitemap_360_sp.txt$ /sitemap_360_sp.php last;????????rewrite ^/sitemap_baidu_sp.xml$ /sitemap_baidu_sp.php last;????????rewrite ^/sitemap_m.xml$ /sitemap_m.php last;
保存后,执行如下命令,平滑重启 nginx 即可:
/usr/local/nginx/sbin/nginx –s reload
三、PHP 代码
将如下方法放到贴到网站入口文件 index.php 中的第一个 <?php 之后即可:
//获取UA信息$ua = $_SERVER[‘HTTP_USER_AGENT’];//将恶意USER_AGENT存入数组$now_ua = array(‘FeedDemon ‘,‘BOT/0.1 (BOT for JCE)’,‘CrawlDaddy ‘,‘Java’,‘Feedly’,‘UniversalFeedParser’,‘ApacheBench’,‘Swiftbot’,‘ZmEu’,‘Indy Library’,‘oBot’,‘jaunty’,‘YandexBot’,‘AhrefsBot’,‘MJ12bot’,‘WinHttp’,‘EasouSpider’,‘HttpClient’,‘Microsoft URL Control’,‘YYSpider’,‘jaunty’,‘Python-urllib’,‘lightDeckReports Bot’);//禁止空USER_AGENT,dedecms等主流采集程序都是空USER_AGENT,部分sql注入工具也是空USER_AGENTif(!$ua) {????header(“Content-type: text/html; charset=utf-8”);????die(‘请勿采集本站,因为采集的站长木有小JJ!’);}else{????foreach($now_ua as $value )//判断是否是数组中存在的UA????if(eregi($value,$ua)) {????????header(“Content-type: text/html; charset=utf-8”);????????die(‘请勿采集本站,因为采集的站长木有小JJ!’);????}}
四、测试效果
如果是 vps,那非常简单,使用 curl -A 模拟抓取即可,比如:
模拟宜搜蜘蛛抓取:
1 | curl –I –A ‘YisouSpider’ zhangge.net |
模拟 UA 为空的抓取:
1 | curl –I –A ” zhangge.net |
模拟百度蜘蛛的抓取:
1 | curl –I –A ‘Baiduspider’ zhangge.net |
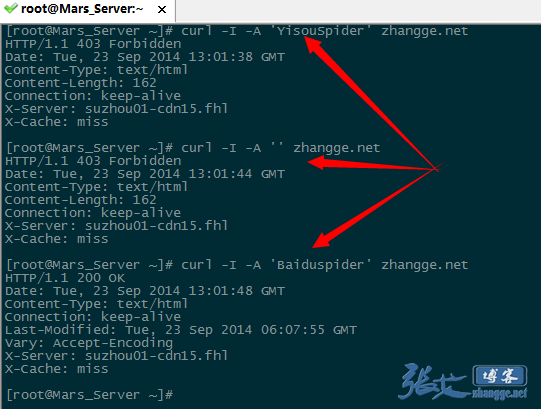
三次抓取结果截图如下:
可以看出,宜搜蜘蛛和 UA 为空的返回是 403 禁止访问标识,而百度蜘蛛则成功返回 200,说明生效!
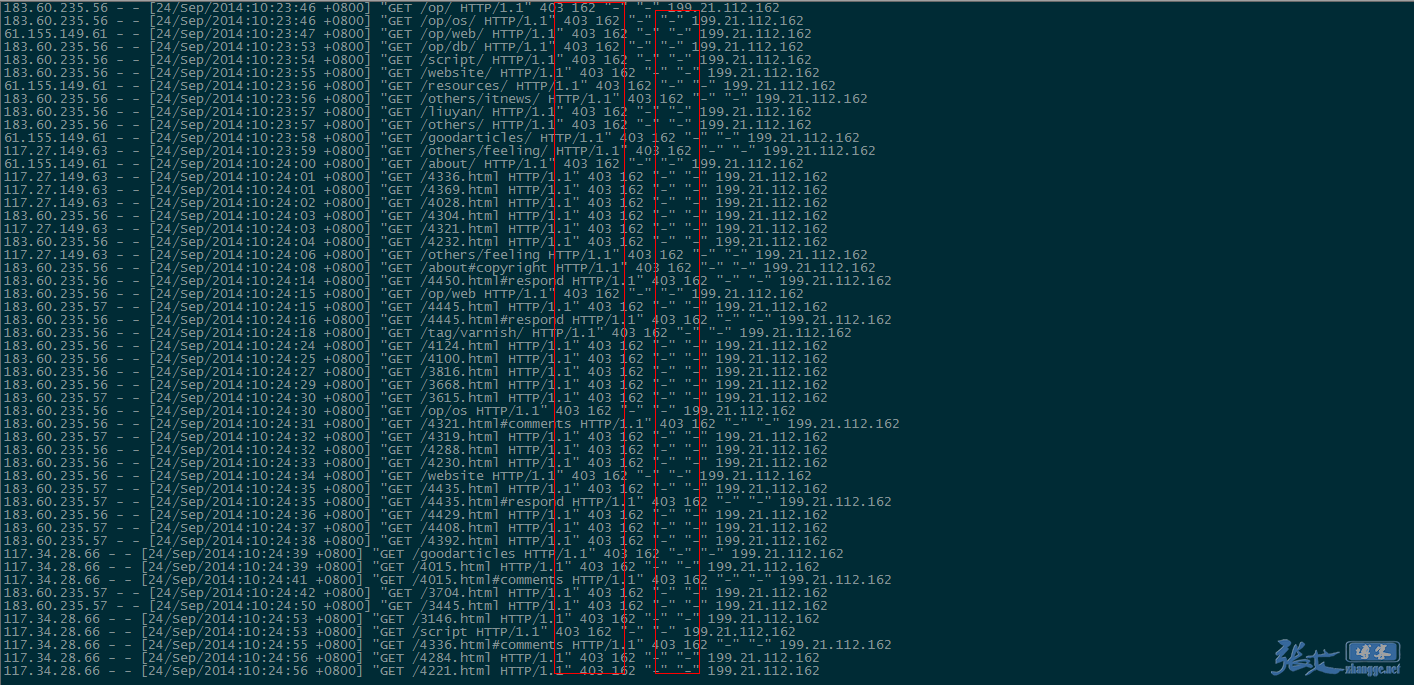
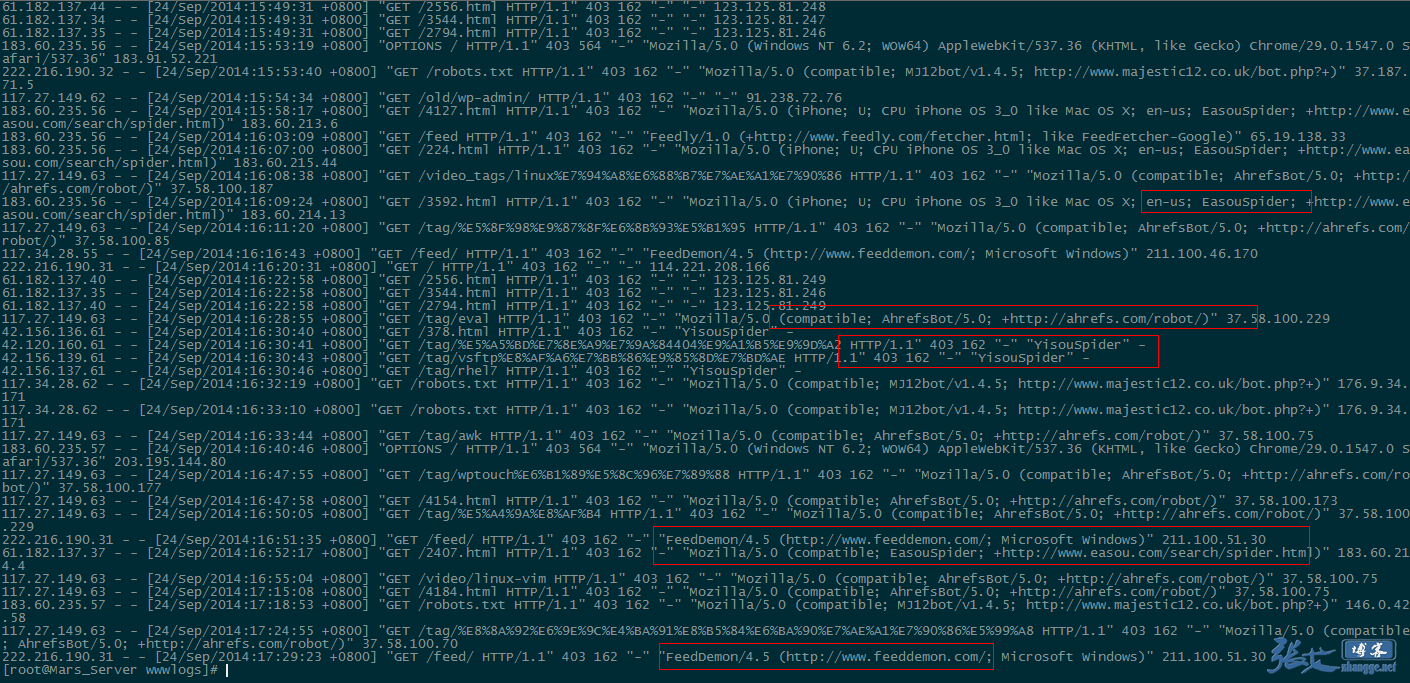
补充:第二天,查看 nginx 日志的效果截图:
①、UA 信息为空的垃圾采集被拦截:
②、被禁止的 UA 被拦截:
因此,对于垃圾蜘蛛的收集,我们可以通过分析网站的访问日志,找出一些没见过的的蜘蛛(spider)名称,经过查询无误之后,可以将其加入到前文代码的禁止列表当中,起到禁止抓取的作用。
五、附录:UA 收集
下面是网络上常见的垃圾 UA 列表,仅供参考,同时也欢迎你来补充。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | FeedDemon???????????? 内容采集 BOT/0.1 (BOT for JCE) sql注入 CrawlDaddy????????????sql注入 Java??????????????????内容采集 Jullo???????????????? 内容采集 Feedly????????????????内容采集 UniversalFeedParser?? 内容采集 ApacheBench?????????? cc攻击器 Swiftbot??????????????无用爬虫 YandexBot???????????? 无用爬虫 AhrefsBot???????????? 无用爬虫 YisouSpider?????????? 无用爬虫(已被UC神马搜索收购,此蜘蛛可以放开!) MJ12bot?????????????? 无用爬虫 ZmEu phpmyadmin?????? 漏洞扫描 WinHttp?????????????? 采集cc攻击 EasouSpider?????????? 无用爬虫 HttpClient????????????tcp攻击 Microsoft URL Control 扫描 YYSpider??????????????无用爬虫 jaunty????????????????wordpress爆破扫描器 oBot??????????????????无用爬虫 Python–urllib???????? 内容采集 Indy Library??????????扫描 FlightDeckReports Bot 无用爬虫 Linguee Bot?????????? 无用爬虫 |
六、参考资料
问说:http://www.uedsc.com/acquisition.html
服务器反爬虫攻略:Apache/Nginx/PHP禁止某些User Agent抓取网站


{kind=link}
{kind=link}
{kind=link}